Pipelined database operations with python-oracledb 2.4
Python-oracledb 2.4 introduces pipelining functionality to improve the performance and scalability of your Python applications for Oracle Database. Pipelining is simple in python-oracledb: you add operations such as INSERT and SELECT statements to a “pipeline” object, send that object to the database which processes the statements, and finally all the results will be returned to the application. Since the API is asynchronous, your application can submit the pipeline and continue with other local tasks while the database is doing its processing. This lets the database server and the application be kept busy, giving efficiencies and letting them work concurrently instead of waiting on each other for statements and results to be submitted/fetched.
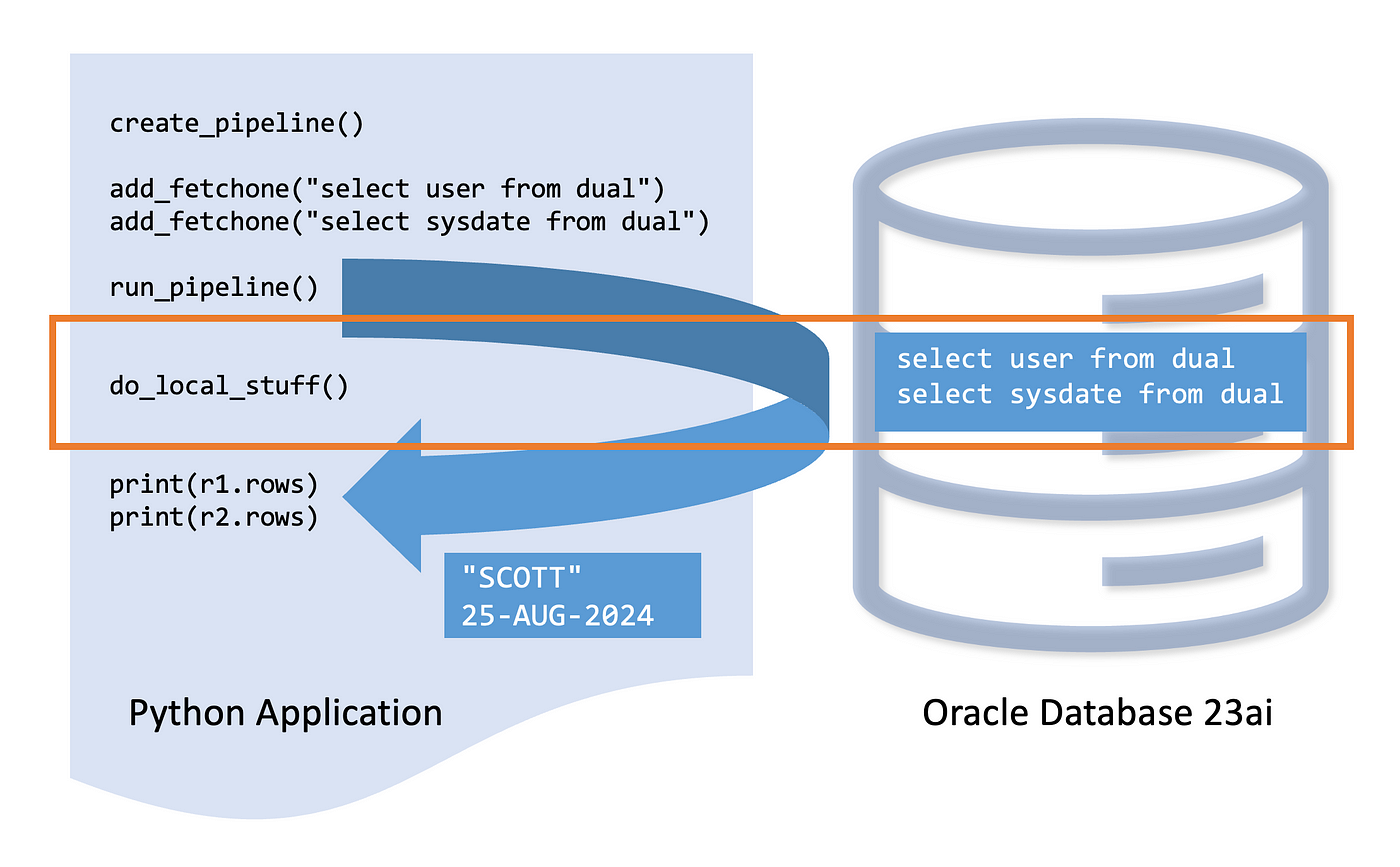
Pipelining Overview
Pipelining is useful when many small database operations need to be performed in rapid succession. It is supported by various drivers, including JDBC, Oracle Call Interface, ODP.NET, and Python.
The benefits of Oracle Database 23ai Pipelining:
- Your app can do local work at the same time the database is processing statements.
- Your app doesn’t have to wait on one database response before sending a second statement.
- Your app is kept busy.
- After the database finishes one statement, it doesn’t have to wait for your app to fetch results and send a second statement.
- The database is kept busy.
- Fewer round-trips to the database: reduced Oracle network listener wake-ups. Reduced interrupts. More efficient network usage.
- Better overall system scalability.
The reduction in round-trips to the database is a significant contributor to pipelining’s performance improvement in comparison to executing the equivalent SQL statements individually on a slow network. But, even with high-speed networks, where the performance benefit of pipelining may be lower, the database and network efficiencies of pipelining can still help system scalability.
Pipelining in Python is available via python-oracledb’s Async classes: this means you must use the default Thin mode of python-oracledb, and use it in an asynchronous programming style. Pipelining works with Oracle Database 23ai. (Although you can actually use the new python-oracledb pipelining API when connected to older database versions, you won’t get the internal pipelining behavior and benefits — this is recommended only for migration or compatibility reasons). You can get Oracle Database 23ai from Oracle Database Software Downloads.
You can use the following python-oracledb calls to add operations to a pipeline:
add_callfunc()- calling a stored PL/SQL functionadd_callproc()- calling a stored PL/SQL procedureadd_commit()- committing the current transaction on the connectionadd_execute()- executing one SQL statementadd_executemany()- executing one SQL statement with many bind valuesadd_fetchall()- executing a query and fetching all the resultsadd_fetchmany()- executing a query and fetching a set of the resultsadd_fetchone()- executing a query and fetching one row
Note the database processes the pipelined statements sequentially. The concurrency gain is betwen your application’s local work and the database doing its work.
Query results or OUT binds from one operation cannot be passed to subsequent operations in the same python-oracledb pipeline. If you need to use results from a pipeline operation in a subsequent database step, you can use multiple pipelines.
Social Network Example
An example use case is a social networking site. After you log in, your home page needs to show information gathered from various sources. It might show how many of your friends are also logged in. A news feed might show the top news items of the day. Current and forecast temperatures could be shown. Some of this data could be in a database, but require several distinct queries to fetch. Finding the current temperature might require Python calling out to a service to return that data. This is great use case for Pipelining: the distinct queries can be sent in a pipeline for processing, while the remote temperature sensor data is gathered at the same time.
The full code for this simple example web app is in pipeline-blog-quart.py.
The app needs to run asynchronously, so a framework that supports this is needed. I semi-arbitrarily chose the Quart micro-framework, which has a relationship to Flask. Flask’s async support isn’t complete enough for a full async application.
The main body is:
app = Quart(__name__, )
# Users home page
@app.route("/homepage")
async def homepage():
r = await getdata() # Calls the database and remote temperature sensor
return buildhtml(r) # Puts the data into an HTML page and returns it for display
@app.before_serving
async def setup():
start_pool() # Start a pool of connections
await create_schema() # Create the demo tables
if __name__ == "__main__":
print(f"Try loading http://127.0.0.1:{PORT}/homepage in a browser")
app.run(port=PORT)I chose to show how a connection pool would be used, since connection pooling would be important for any actual multi-user app to do, and is something that is worth taking care to implement and configure correctly.
Then, for demo purposes, the app creates the schema and loads sample data when it starts. (This loading is itself another example use case for pipelining since multiple SQL statements are needed. See create_schema() in the app).
Whenever the /homepage URL is invoked, the getdata() routine is called. This is where Pipelining really stars. The method does the database queries and accesses the temperature sensor concurrently. When all the data has been gathered, it is formatted into an HTML page by buildhtml() which is then displayed by Quart. The getdata() method and the external sensor method get_current_temperature() look like:
async def get_current_temperature():
return randint(0, 50) # fake what the thermometer returned - in Celsius of course
async def getdata():
global pool
async with pool.acquire() as connection:
# Create a pipeline and define the operations
pipeline = oracledb.create_pipeline()
pipeline.add_fetchone("select high from weather")
pipeline.add_fetchall("select name from friends where active = true")
pipeline.add_fetchall("select story from news order by popularity fetch next 5 rows only")
# Run the pipeline and non-database operations concurrently
current_temp, result_pl = await asyncio.gather(
get_current_temperature(),
connection.run_pipeline(pipeline)
)
# Extract the database pipeline query results
t = result_pl[0].rows[0][0] # max forecast temperature
f = [n for n, in result_pl[1].rows] # list of active friends
n = [s for s, in result_pl[2].rows] # top 5 news stories
return { "current": current_temp, "forecast": t, "friends": f, "news": n }This creates a pipeline with three SELECT statements. By using asyncio.gather(), the pipeline is executed in parallel with a call to get_current_temperature() (which fakes reading an external thermometer). When all the data is available, it is returned in a dict.
Starting the app and loading the home page in a browser gives a page like:
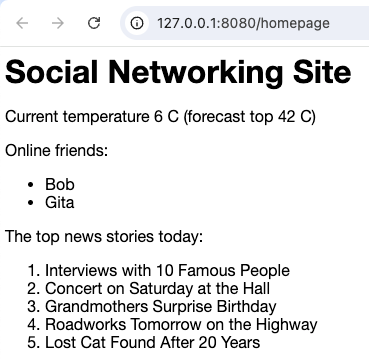
The reading of the thermometer and the database work are executed concurrently: both the app and the database are kept busy. The application response time is reduced, making users happier. When the database is doing its work, it is kept busy with fewer interrupts and pauses, making it more efficient. Overall system scalability has improved.
Performance Example
An example pipeline with more operations makes it easier to see performance benefits. [Update: see my new blog Pipelined database operation performance redux with python-oracledb: very impressive which showcases a more complete benchmark where Pipelining results in 529% more transactions per second].
Let’s start with a program that doesn’t use Pipelining (see pipeline-bm-non.py). It uses the existing async functionality of python-oracledb but every statement is executed sequentially:
# No Pipelining
for i in range(50):
await connection.execute("insert into TestTempTable values (:1, :2)", [i + 1, f"Value {i + 1}"])
await connection.execute("""
update TestTempTable set Description = Description || ' (modified)'
where mod(ID, 2) = 1""")
for i in range(50):
await connection.execute("insert into TestTempTable values (:1, :2)", [i + 51, f"Value {i + 51}"])
await connection.commit()
rows = await connection.fetchall("select * from TestTempTable")Note the demo executes lots of the same INSERT statement. This is simply to showcase a “larger” pipeline length. In production non-pipelining and pipelining code, you should use executemany() for such a flow.
But, putting aside that comment, each of the statements executed will require a round-trip.
To cut down the number of round-trips, the script can be converted to use Pipelining (see pipeline-bm.py):
# Pipelining with Oracle Database 23ai
pipeline = oracledb.create_pipeline()
for i in range(50):
pipeline.add_execute("insert into TestTempTable values (:1, :2)", [i + 1, f"Value {i + 1}"])
pipeline.add_execute("""
update TestTempTable set
Description = Description || ' (modified)'
where mod(ID, 2) = 1""")
for i in range(50):
pipeline.add_execute("insert into TestTempTable values (:1, :2)", [i + 51, f"Value {i + 51}"])
pipeline.add_commit()
pipeline.add_fetchall("select * from TestTempTable")
result = await connection.run_pipeline(pipeline)This will require only one round-trip, initiated when run_pipeline() is called.
On my laptop, with the database running locally in an emulated container environment, typical end-to-end timing results I saw were:
$ python3 pipeline-bm.py; python3 pipeline-bm-non.py
pipelining: 0.34 seconds
no pipelining: 0.46 secondsThis particular result is a 26% decrease in end-to-end time for the application’s database workload. Your results will vary — on slower networks you will see even more benefit. The Pipelined application was much more efficient. I could also have utilized parallelism to allow the app to continue other work while the database was processing statements (as shown in the social networking example), giving further gains to overall app performance.
Conclusion
Pipelining in Oracle Database 23ai is a technique to improve application performance and system scalability by keeping the database busy while allowing applications to concurrently continue local work. Pipelining is available to applications using python-oracledb, JDBC, ODP.NET and Oracle Call Interface.
Pipelining is useful when many small database operations need to be performed in rapid succession. It is most effective when networks costs are high. But even on fast networks, or with a small number of operations, pipelining provides system benefits.
The performance benefits can be significant: see the new blog Pipelined database operation performance redux with python-oracledb: very impressive.
The new Pipeline support in python-oracledb 2.4 builds on the existing support for asyncio. It is available in Thin mode via new Pipeline classes. In this release it is marked ‘experimental’ to give you time to test and suggest small or big changes before we finalize the API. We have tested with asyncio. Your feedback about the behavior with other alternatives like uvloop would be invaluable.
Pipelining References
- Python-oracledb documentation: Pipelining Database Operations
- Blog: Using Pipelining for Efficient Schema Creation
- Blog: Introducing Pipelining and Asynch Programming for Oracle Database 23ai
- Oracle Call Interface documentation: OCI Pipelining
- Blog: What’s in ‘Oracle DB 23c Free Developer Release’ for Java Developers
- JDBC Documentation: Support for Pipelined Database Operations
- Blog: Asynchronous ODP.NET and Pipelining: Improve Performance by Reducing Latency
Installing or Upgrading python-oracledb
You can install or upgrade python-oracledb by running:
python -m pip install oracledb --upgradeThe pip options --proxy and --user may be useful in some environments. See python-oracledb Installation for details.
Python-oracledb References
Home page: oracle.github.io/python-oracledb/index.html
Installation instructions: python-oracledb.readthedocs.io/en/latest/installation.html
Documentation: python-oracledb.readthedocs.io/en/latest/index.html
Release Notes: python-oracledb.readthedocs.io/en/latest/release_notes.html
Discussions: github.com/oracle/python-oracledb/discussions
Issues: github.com/oracle/python-oracledb/issues
Source Code Repository: github.com/oracle/python-oracledb
